Goed, ik had dus een dataset en daarmee kon ik redelijke voorspellingen doen ook. Tijd dus om het héle ontwerp van Lynn eens te maken. Dan is gelijk de eerste vraag: wat moet Lynn dan precies doen? Nou ja, mij werk uit handen nemen. Ik wil niet meer lastig gevallen worden met “kan ik deze NDA tekenen”. Het doel van Lynn was dus: wees een site die zegt of je die NDA kunt tekenen. Document uploaden, geen gezeur, ja je kunt tekenen.
Ik had zo’n systeem nog niet eerder gezien. Bestaande systemen ondersteunen advocaten in hun praktijk. Het grote voordeel is dan dat ze sneller lezen en altijd even accuraat. Je krijgt dan een document met geel gemarkeerde secties waar iets raar mee is, en je weet dat de rest dan dus standaard is. (Het is ergens heel raar dat bedrijven elkaar doodgooien met teksten waarvan een robot al zegt, dit is standaard lekker laten gaan, maar dat is een andere discussie.) Maar je moet het zelf nog steeds lezen en uiteindelijk je conclusie trekken.
Zo’n advies, gewoon ja of nee zeggen. Hoe moet dat eruit zien. Uit mijn praktijk weet ik dat mensen vaak alleen vragen of er dealbreakers in staan. Grote dingen die heel pijnlijk zijn. Een hele lange termijn. Een boetebeding. Exclusiviteit of een concurrentieverbod. Dat werk. Als je die ziet, dan mag er niet getekend worden.
Dan zijn er nog andere dingen die best vervelend kunnen zijn maar niet perse een dealbreaker. Ja, jij zit in Nederland en men wil Taiwanees recht, dat is niet handig maar even serieus, gaat er echt een rechtszaak komen hiervan? Dat wil je dus wel wéten maar om de NDA daar nu meteen op af te keuren is ook zo wat. Ik noem dit de essentials.
En dan heb je nog de boilerplate, de volkomen standaard tekst die iedereen van elkaar overneemt maar werkelijk niets relevants bevat. Dat de kopjes informatief zijn. Dat de partijen verklaren te mogen tekenen. Dat dit de gehele overeenkomst is. Dat herkent Lynn echt vrijwel perfect (wat niet raar is, in veel gevallen zou een pure string vergelijking minstens zo goed werken) maar niemand wil het weten. Dat moet dus zéér terughoudend terugkomen in de uitvoer.
Met deze opzet komt het erop neer dat Lynn dus allereerst kijkt of er dealbreakers in het document staan. Zo ja, dan is het advies om niet te tekenen. Zijn er essentials met problemen, dan mag je tekenen mits je daar even naar kijkt. (Maar zijn het er te veel, wat ik maar even arbitrair definieer als 30% van de essentials) dan mag je alsnog niet tekenen. En de boilerplate die is er maar dat betekent verder niets. Niemand gaat een NDA weigeren omdat er niets staat over hoe informatief de kopjes zijn.
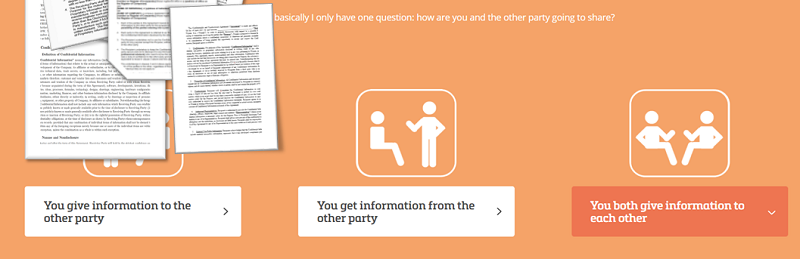
Bij bovenstaande zit wel nog een impliciete aanname, namelijk aan welke kant van de tafel je zit. In het jargon van de NDA-jurist (ja, die bestaat) heb je zogeheten give, get en mutual NDA’s. Een give NDA is geschreven voor de partij die informatie geeft, en is dus heel streng in zijn voordeel. Een get NDA is er juist voor de ontvangende partij, en de mutual NDA probeert beiden even hard te beschermen. (Protip: vraag altijd de mutual NDA, dat scheelt héél veel onderhandelen.)
Je moet dus weten welke van de drie situaties je te maken hebt. Dat is dan ook de vraag (en de enige vraag) die NDA Lynn je stelt. Ga je geven, ontvangen of samen delen? Ik vraag nog meer, maar dat is optioneel en vooral voor de statistieken. Eigenlijk alleen de vraag “in welk land zit u” komt terug in het antwoord: als dat niet hetzelfde is als de rechts- en forumkeuze dan krijg je daar een waarschuwing over.
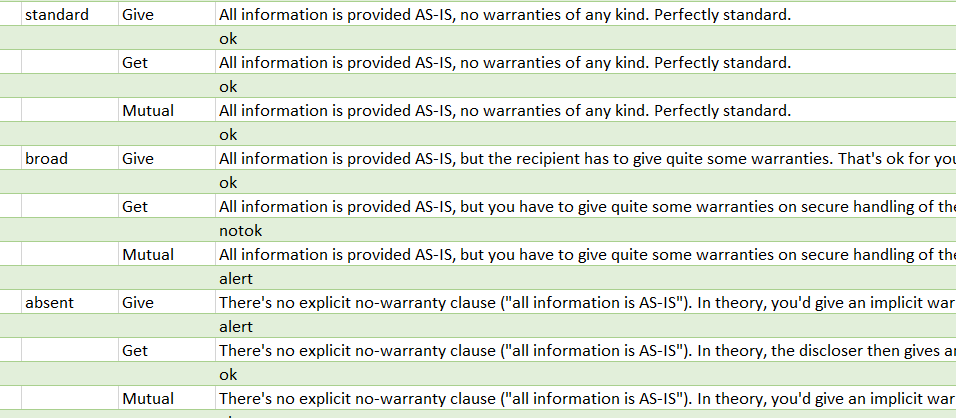 Blijft over: wat ga je zeggen. Daarvoor schrijf ik een uitvoertabel, die per clausule per smaak per situatie aangeeft wat het antwoord moet zijn. Hierboven zie je een klein stukje daarvan: dit is de uitvoer voor de categorie “warranties” oftewel garanties. Wat moet je zeggen als deze standaard of juist breed gevraagd worden, of als er geen garanties in staan. Je ziet dat het antwoord net anders is als je in de give dan wel in de get of mutual situatie zit.
Blijft over: wat ga je zeggen. Daarvoor schrijf ik een uitvoertabel, die per clausule per smaak per situatie aangeeft wat het antwoord moet zijn. Hierboven zie je een klein stukje daarvan: dit is de uitvoer voor de categorie “warranties” oftewel garanties. Wat moet je zeggen als deze standaard of juist breed gevraagd worden, of als er geen garanties in staan. Je ziet dat het antwoord net anders is als je in de give dan wel in de get of mutual situatie zit.
En dan zijn we er. Document tekst extraheren, met een ML model de zinnen classificeren, de zinnen bij elkaar rapen, van de clausules het juiste smaakje bepalen, in de uitvoertabel opzoeken welke uitvoer je moet geven en klaar is Kees. Of Lynn dan.
We testen, en komen de nodige probleempjes tegen. Zo voegen we taaldetectie toe (“Sorry, Portugese NDA’s worden niet ondersteund”), is het extraheren van tekst uit PDF net wat ingewikkelder en staat er soms gewoon rommel in een document. Maar dat is allemaal op te lossen. Tijd om de markt op te gaan.
(Dit is de derde van vijf vakantieberichten.)
Arnoud
Wat een super toffe serie Arnoud!
Zo lezende door het derde deel bekroop me toch het gevoel dat een stukje van gisteren wellicht toch enige nuance behoeft:
Je hebt tot nu toe een flink aantal ontwerpkeuzes toegelicht, bijvoorbeeld opdelen in zinnen in plaats van paragrafen (clausules), de specifieke onderverdeling in tags, toepassen van regexp voor bepaalde data, het bepalen van threshold percentages voor ja/nee beslissingen, etc. Niet allemaal heel voor de hand liggende keuzes, gebaseerd op veel proberen en testen, en ik zou dat dan toch zien als ‘het algoritme’ wat voor een groot deel bepaalt of Lynn correct werkt of niet en waar een eventuele concurrent (in het algemeen…) zijn voordeel mee zou kunnen doen. Je zou de redenatie dus ook deels kunnen omdraaien: op het moment dat je weet hoe een goed werkend algoritme/architectuur in elkaar zit voor jouw toepassing is het labelen van je trainingsdata hoofdzakelijk veel werk maar verder weinig creatief. Het vergt soms vakexpertise om dat goed te doen en het bepaalt inderdaad de kwaliteit van je systeem, maar ik zie jouw oorspronkelijke uitspraak dus wat minder zwart-wit. De ML zelf is eigenlijk nooit spannend, maar de duct tape eromheen is in sommige gevallen toch handig om geheim te houden.Dat zie ik, maar a) als IT-er vind ik die ontwerpkeuzes geen algoritmes en b) zonder adequate dataset doen al die regexpen en groepen geen ene bal. Ik zie het net als in de cryptografie, daar is de sleutel het enige dat geheim moet blijven voor een kwaliteitssysteem en bij AI gaat het om de dataset. Iedereen kan bedenken dat je met een regexp op “San Jose” kunt filteren in je rechtskeuze-clausule en dan weet dat dat de rechtbank is.
Als je dat geheim houdt, is dat volgens mij meer om geheim te houden dat je met ducttape werkt 😛 Tegen investeerders zeggen dat je een AI hebt die teksten leest, is beter dan dat je zegt “we halen alle steden ter wereld met brute force door deze alinea en zo weten we welke rechtbank gekozen is”. Maar de grap is dat een AI minder goed werkt dan die regexp – die overigens weinig meer is dan 280 case insensitive string matches, ik heb niet eens geoptimaliseerd op common string prefixes. De lijst is in volgorde van populairste rechtbank.
En ja, de dataset labelen is weinig creatief, hoewel volgens mij de categorieën door mij net slim genoeg gekozen zijn om me een auteursrecht op dat lijstje te geven.
Het algoritme is overigens een boosted trees implementatie van BigML. Vrijwel alles van hoe dat werkt, is door hen gepubliceerd. In ieder geval kan iedereen exact diezelfde configuratie nabouwen.
De indruk die ik krijg is dat het hier gaat om een rule based system. Klopt dat?
Wat versta jij daaronder? Er is een ML model dat zegt wat welke clausule is, en een set regels die bepalen wat dat voor consequenties heeft.