
Stockfotodatabank Getty Images heeft Stable Diffusion-maker Stability AI aangeklaagd, las ik bij Tweakers. Stability AI zou haar plaatjesgenerator (mede) hebben getraind op ‘miljoenen’ afbeeldingen van Getty, en daarbij de verkeerde (lees: te goedkope) licentie hebben afgenomen om bij de bronbeelden te kunnen. Het roept natuurlijk de vraag op, is het überhaupt inbreuk op auteursrechten als je een AI traint op beschermde werken?
Ik heb al eerder geblogd over je foto als datapunt in iemands AI, waarbij de kern is of het leren van een foto telt als een inbreuk op het auteursrecht. Hoofdregel van het auteursrecht is immers dat een stukje van het werk in de uitvoer terecht komt, en als ik alleen maar de onderliggende informatie extraheer dat “ondergaande zon” hoort bij een halfronde gelige bol, dan zie ik niet hoe ik een auteursrecht schend.
Dit soort plaatjesgeneratoren werkt alleen subtiel net iets anders. Ze extraheren niet de informatie van hoe dingen eruit zien (zoals een leerling-kunstenaar zou doen) om daar vervolgens nieuwe werken mee te maken. Zoals Matthew Butterick (die ook Github aanklaagt over hun AI) uitlegt:
The first phase in diffusion is to take an image (or other data) and progressively add more visual noise to it in a series of steps. (…) At each step, the AI records how the addition of noise changes the image. By the last step, the image has been “diffused” into essentially random noise. The second phase is like the first, but in reverse.Het systeem bewaart dus een soort-van gecomprimeerde versie van elke bronafbeelding, waarbij bij elke afbeelding termen onthouden worden waar ze over gaan. Butterick laat dit zien met deze afbeelding:

De originele afbeelding linksboven wordt via twee stappen omgezet naar ruis, wat je kunt zien als een soort-van hash, een soort-van compressie. Reconstructie gebeurt door die ruis als invoer te nemen en via een omgekeerde functie te vertalen naar een bronafbeelding.
De volgende stap is het genereren van nieuwe afbeeldingen. Dit illustreert Butterick met de volgende afbeelding, die laat zien hoe men van twee portretafbeeldingen een nieuwe maakt (klik voor groot):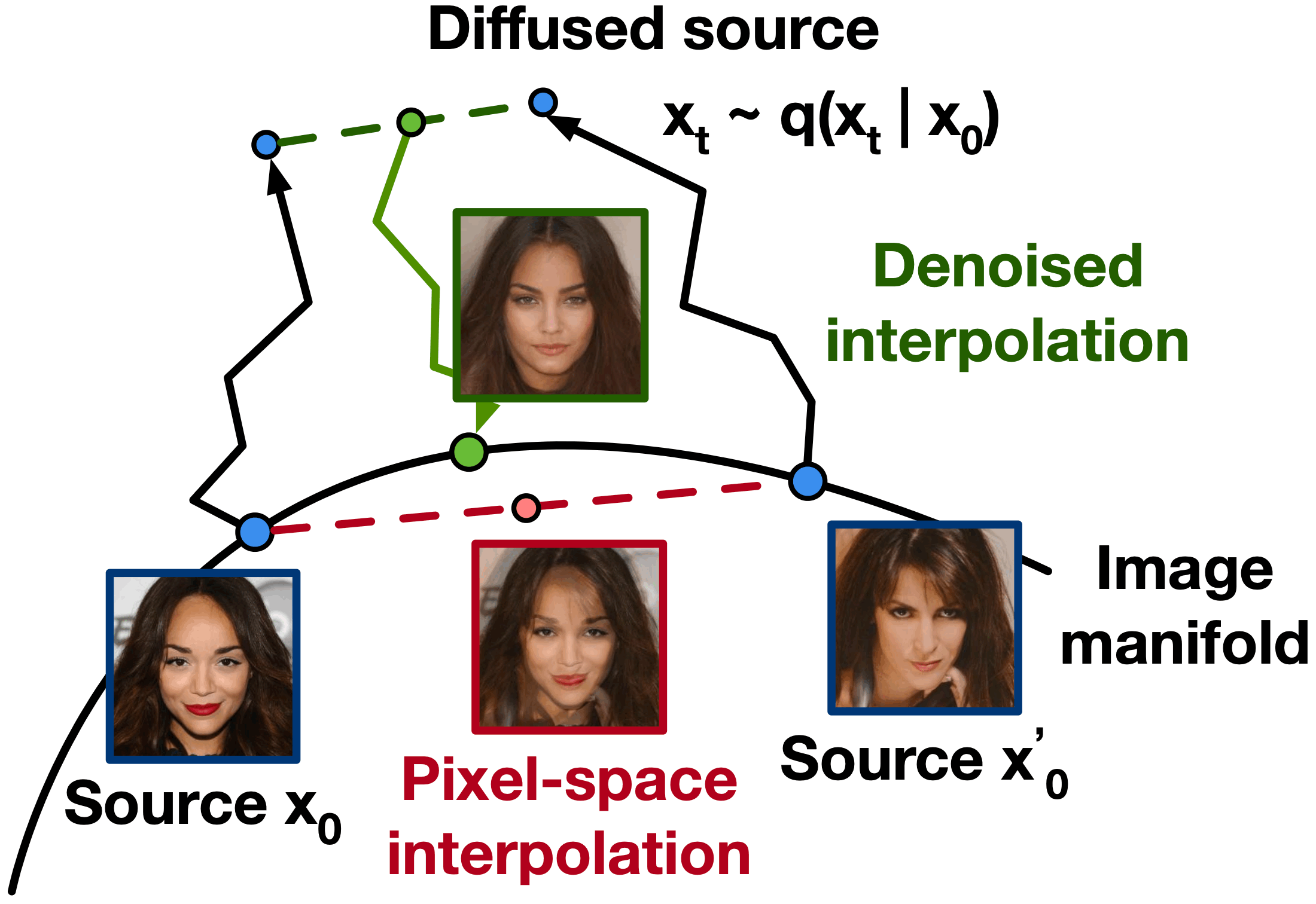
De groene afbeelding is waar het uiteindelijk om gaat. Deze wordt niet gemaakt door pixels samen te voegen (zoals bij de rode) maar door de soort-van hashes van de twee bronafbeeldingen samen te voegen en daar de reconstructie op los te laten.
Het wordt dan nog iets complexer door de constructie van prompts, die zeg maar bepalen welke bronafbeeldingen worden gebruikt. Maar de kern blijft: bronafbeeldingen worden in soort-van gecomprimeerde vorm samengevoegd en daaruit wordt dan een nieuwe afbeelding gereconstrueerd. Deze techniek kent geen analogie, maar heel breed gekeken zou je dit wellicht een vorm van collageren kunnen noemen? Daar gaat het om kleine stukjes uit vele werken, hier meer om vage versies van vele werken.
Kom ik terug bij die hoofdregel: als een stukje van een werk herkenbaar in andermans werk zit, en dat stukje geeft blijk van het creatief vermogen van de maker van het origineel, dan is sprake van inbreuk (tenzij citaatrecht et cetera). De analyse van Butterick laat zien dat er stukjes van bronwerken in gegeneerder werken terechtkomen, zij het vaag. Dat roept de vraag op of die stukjes blijk-van-creativiteit nog wel aan te wijzen zijn – nog los van de vraag hoe een individuele rechthebbende kan aantonen dat zijn werk gebruikt is.
Bij Getty is dat laatste iets minder een issue, als bewezen is dat er miljoenen afbeeldingen in het systeem ingelezen zijn dan zou de inbreuk vrij snel vast moeten staan. Alleen is het de vraag of dit wel “inbreuk” te noemen is, gezien Stability AI op basis van een licentie de afbeeldingen gebruikte. En mogelijk zijn ze dan de voorwaarden te buiten gegaan, maar dat noemen we eerder contractuele wanprestatie dan een rechtenschending. (Dat heeft gevolgen voor de schadeclaim, proceskosten enzovoorts.)
Het zou in het algemeen wel raar zijn als vaststaat dát er grootschalig allerlei rechten worden geschonden door dit transformatieve proces, maar dat geen enkele rechthebbende kan optreden tenzij deze door de vage schimmen heen kan prikken en zijn individuele foto aanwijzen.
Arnoud
Deze video van Jake Watson probeert af te wegen of het (in de VS relevante) principe van Fair Use voor de Class Action die daar gestart is, van toepassing gaat zijn: video Over het algemeen lijkt het me goed dat de rechtszaken plaatsvinden. Ook al bij het bericht op Tweakers worden reacties geplaatst van mensen waarvoor het allemaal klip en klaar is. Terwijl die ver in het grijze gebied zit. Dit is geen Napster of PirateBay verhaal.
Is dit uiteindelijk niet gewoon simpel contract recht? Als de licentie voorwaarden van Getty zeggen dat je voor het gebruik van afbeeldingen voor AI trainingsdoel einden licentie X nodig hebt, maar je het stiekem doet met licentie Y. Ik als leek zou dan zeggen je bent als commerciële partij akkoord gegaan met de voorwaarden en pleegt contract breuk.
Dat zo dan betekenen dat je zonder licentie de afbeeldingen wel voor AI training mag gebruiken en met licentie niet. Dat maakt voor mij de waarde van de licentie negatief.
Maar zonder licentie krijg je geen toegang tot hoge-resolutie afbeeldingen die ook nog eens zonder watermerk zijn. Dus hoe moet je dan trainen?
De grap was juist dat afbeeldingen zoals deze : https://cdn.vox-cdn.com/thumbor/AONcjmTsmmneNfNiUOC72lql5EY=/0x0:768×768/768×768/filters:focal(384×384:385×385)/cdn.vox-cdn.com/uploads/chorusasset/file/24365776/gettyimagesexamplestablediffusion.jpg blijkbaar aantonen dat er ook Getty afbeeldingen zonder licentie gebruikt zijn, waardoor dus het beruchte Getty Image watermerk opeens in AI generated art verschijnt.
Het is mij nooit duidelijk geworden of dat kwam omdat de AI grote lappen Getty-watermarked-data copypaste, of omdat hij “Getty watermerk” associeert met “hoge kwaliteit afbeelding”.
Uit deze zaak weten we dus dat SD heeft getraind op aangekochte afbeeldingen. Die hebben geen watermerk. Daarom neig ik naar de tweede verklaring, de AI plakt watermerken omdat op internet de goede afbeeldingen watermerken hebben.
Als Getty een herkenbaar creatief watermerk had gebruikt, dan zouden ze dus een heleboel AI plaatjesmakers hebben kunnen aanklagen vanwege het maken van auteursrechtinbreuk op het watermerk…
Maar dat brengt be bij het merkrecht; Heeft Getty een rechtsgrond om te klagen over “lage kwaliteit” beelden die de AI genereert, waarbij het watermerk ten onrechte suggereert dat het beeld uit de Getty collectie komt?
Ik heb moeite met dit onderscheid. Als ik bij de autodealer een sleutelhanger koop maar vervolgens met een nieuwe Mercedes de showroom uitrijd spreken we toch ook niet van wanprestatie? (Ja ik begrijp het, andere situatie, eigendomsrecht, geen overdracht, enz.) Een licentieovereenkomst heeft de strekking dat de licentienemer een geldsom moet betalen en de licentiegever bepaald gebruik van het werk moet toestaan. Bestaat de enige verplichting voor de licentienemer dan uit betaling van de geldsom, zodat hij alleen voor die verplichting wanprestatie kan verrichten? Kan de formulering van de licentieovereenkomst daar nog verandering in brengen? Denk aan het onderscheid tussen “de afnemer zal de afbeelding niet commercieel gebruiken” en “deze licentie strekt zich niet uit tot commercieel gebruik”. Pleeg je bij die eerste formulering nog steeds wanprestatie als je de afbeelding commercieel gebruikt nadat het auteursrecht is verlopen?
Da’s een goeie ja. Juridisch is hier sprake van samenloop van onrechtmatige daad (in jouw voorbeeld diefstal) en wanprestatie (het niet meenemen van de gekochte auto). Uit m’n hoofd kun je dan als dealer een vordering wegens OD brengen als het zonder de overeenkomst óók onrechtmatig zou zijn, wat bij diefstal natuurlijk zo is. Maar bij een OD die vooral samenhangt met de overeenkomst (zonder de ovk zou het niet onrechtmatig zijn) kan dat niet.
Ik zou bij een licentie nietcommercieel zeggen dat je een OD pleefgt door wél commercieel te gebruiken. Want zonder overeenkomst was het ook onrechtmatig. Maar als ik te laat betaal, dan pleeg ik geen OD door de foto te gebruiken. Dan pleeg ik alleen wanprestatie.
Het is dat je er meteen al bij zegt dat het voorbeeld van een klager komt, anders had ik het gevraagd.
Het voorbeeeld is namelijk typisch een voorbeeld wat ik inmiddels gewend ben van ingehuurde experts die in rechtzaken hun opinie geven in de VS: cherry picked en niet representatief voor hetgeen ze over klagen.
Het voorbeeld laat netjes zien wat er gebeurt als je traint op een enkel image voor een omschrijving. Als je dat met een gezicht doet dan genereer je datzelfde gezicht terug bij die token. Daarom train je het model niet op een enkele foto van dat gezicht, maar op meerdere vanuit verschillende perspectieven. Het model leert dan niet een afbeelding reproduceren, maar ontdekt de statistische verbanden die al die afbeeldingen aan het token koppelen.
Er zijn wat dat betreft dus twee problemen die tot reproductie van een afbeelding kunnen leiden: 1. Er is op slechts 1 afbeelding voor dat onderwerp getrained of 2. een bepaalde foto kwam meerdere malen (en heel vaak in verhouding met andere foto’s bij dat token) voor in de trainingsset.
Eerste geval geeft Butterick een mooie omschrijving voor, het tweede geval is een voorbeeld van overfitting van het model. Beide zijn ongewenste zaken bij het trainen van het model en vooral een kwestie van goed opletten bij het samenstellen van de trainingset. Het zijn fouten en niet wat het model moet doen.
Een mooi voorbeeld van overtraining zijn filmsterren. Als je die in SD als token invoert krijg je zonder verdere promts altijd foto’s van een red carpet event. Het language model associeert filmsterren met elkaar, dus met de naam van een ster weet het model dat vergelijkbare afbeeldingen onder de token celebrity gevonden kunnen worden. Wat is er oververtegenwoordigd in de foto’s van beroemdheden: foto’s op de rode loper. Dus krijg je een achtergrond met random gibberish die o reclame lijkt die je bij dat soort events op de achtergrond ziet. Dit betekent dus niet dat er een foto van de filmster op de rode loper wordt gereproduceert!
Die reclames zijn vrijwel altijd onleesbare rommel, wat ik ook zou verwachten van watermerken in foto’s. Waarschijnlijk is SD inderdaad getraind op een Getty watermerk, dat is heel praktisch: je kan dan een getty foto met watermerk nemen en in img2image met inpaint het watermerk selecteren en Getty watermerk bij negative promts invullen. Vervolgens voor een tiental randomseeds runnen en grote kans dat er een mooie foto bij zit war de AI het watermerk uit heeft verwijderd voor je. Oeps, daar wordt Getty niet blij van.
Zit er een gecomprimeerde versie van de foto’s in de dataset? Nee dus, maar er kan als je slecht getraind hebt wel een statistische beschrijving inzitten van een specifieke foto die bij de juiste prompts tot een erg lijkende afbeelding leidt. Je moet dan wel de juiste prompt invoeren, dat doet de gebruiker. Met heel gedetailleerde positieve en negatieve promts die een bestaande foto beschrijven kan je samen met de data nog meer foto’s min of meer reproduceren. Dat komt dan wel omdat je een goede omschrijving in het model invoert en een persoon er nu eenmaal op een bepaalde manier uitziet.
Een mooi voorbeeld dat er geen gecomprimeerde foto wordt opgeslagen maar een statistische beschrijving van een idee: kijk wat SD met handen/vingers doet. Daar heeft het model werkelijk geen kaas van gegeten en het gaat vaker fout dan goed. Wat het model dan weer wel heel goed kan is kenmerkende wratten, sproeten en/of moedervlekken beschrijven. Een paar foto’s is voldoende om dat te herkennen, waardoor het model het gezicht soms niet goed kan reproduceren, maar toch alle de voorgenoemde kenmerken kloppen. Een mooi voorbeeld van hoe het model dus statistische kenmerken opslaat die het herkent, niet hele afbeeldingen.
Dus wie reproduceert dan die foto SD of de eindgebruiker? Het is voor mij een brug te ver om te zeggen dat de vectoren die worden opgeslagen de foto beschrijven.
Je kan dit trouwens zelf ook ervaren als je een nVidia GPU hebt met minimaal 8GB VRAM: Met dreambooth kan je een embedding trainen van jouw eigen gezicht, waarmee je afbeeldingen van jezelf kan genereren of jezelf in foto’s kan plaatsen.
Train een embedding met 20 afbeeldingen van jouw gezicht en genereer afbeeldingen. Je zal zien dat gezichten in het algemeen slechter zijn geworden en op jouw zijn gaan lijken. Dit is omdat de embedding alleen jouw foto’s had en dus niet goed kon onderscheiden wat jouw gezich nu zo uniek maakt tov andere gezichten
Train dezelfde embedding opnieuw met jouw 20 foto’s en 200+ foto’s van willekeurige gezichten. De embedding zal herkennen wat jouw gezicht uniek maakt en verminkt niet langer andere gezichten.