 De Nederlandse politieke partijen D66 en CDA roepen het kabinet dinsdag in een motie op toezichthouder op te zetten die het gebruik van algoritmes bij de overheid in de gaten houdt. Dat las ik bij Tweakers maandag. De macht van algoritmes is een steeds grotere angst aan het worden: ze zijn niet transparant, ze kunnen al snel discrimineren of oneerlijk behandelen en ambtenaren voelen zich vaak verplicht om te doen wat het algoritme zegt in plaats van hun eigen afwijkende opvatting over de zaak door te zetten. Een loffelijk idee, alleen vergeten ze weer waar het eigenlijk om gaat: it’s the data, stupid.
De Nederlandse politieke partijen D66 en CDA roepen het kabinet dinsdag in een motie op toezichthouder op te zetten die het gebruik van algoritmes bij de overheid in de gaten houdt. Dat las ik bij Tweakers maandag. De macht van algoritmes is een steeds grotere angst aan het worden: ze zijn niet transparant, ze kunnen al snel discrimineren of oneerlijk behandelen en ambtenaren voelen zich vaak verplicht om te doen wat het algoritme zegt in plaats van hun eigen afwijkende opvatting over de zaak door te zetten. Een loffelijk idee, alleen vergeten ze weer waar het eigenlijk om gaat: it’s the data, stupid.
Aanleiding voor het voorstel is eerdere berichtgeving van de NOS over de macht van algoritmes. Schokkend vond ik vooral dat niet duidelijk was waar en hoe men geautomatiseerde besluitvorming toepast, de NOS had vele wob verzoeken nodig om een en ander een tikje inzichtelijk te krijgen. De richtlijn moet duidelijk maken in welke gevallen gebruik van algoritmes wel of niet gerechtvaardigd is. Of er een volledig nieuwe toezichthouder moet komen of dat bijvoorbeeld de Autoriteit Persoonsgegevens extra bevoegdheden krijgt, moet nog worden besloten.
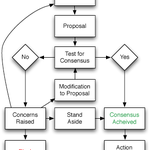
Een algoritme is een reeks instructies die door een computer wordt uitgevoerd, zo meldt de NOS netjes. Alleen hebben we het hier niet over algoritmes in klassieke zin, zoals in het stroomschema hier rechtsboven. Een klassiek algoritme is als een taartrecept: doe eerst dit, als de temperatuur hoog genoeg is doe dan dat, doe daarna zus tenzij X want dan zo. En computers gaan dat dan rechtlijnig uitvoeren. (Kennen jullie die van de programmeur die totaal uitgeput uit zijn douche werd gehaald? Op de shampoofles stond namelijk: haren natmaken, shampoo aanbrengen, uitspoelen, herhalen.)
Dergelijke algoritmes worden top-down ontworpen. Begin met de hoofdlijnen, zoek de simpele randgevallen en voeg daar uitzonderingen voor toe, draai het een paar keer en voeg extra uitzonderingen of bijzondere regels toe. Dat groeit door de tijd heen, maar in principe is elke stap bewust genomen en iedere uitbreiding weloverwogen. In theorie is daarmee iedere stap uit te leggen.
De algoritmes waar dit voorstel over gaat, zijn echter geen klassieke algoritmes. Ik zou dit haast kunstmatige intelligentie noemen maar het is gewoon machine learning: het zoeken naar trends en verbanden op basis van grote bakken met data. Eigenlijk gewoon statistiek: in deze bak data zijn dit de fraudeurs en dit niet, en dan flink doorrekenen wat die gemeenschappelijk hebben om zo een voorspellende functie te bedenken die voor een nieuwe aanmelding zegt of deze fraudeur is.
Die voorspellende functie, geladen met die data, is dan een algoritme in de zin dat het een reeks instructies is – maar praktisch gezien is het onvergelijkbaar met die klassieke algoritmen. Sterker nog: ik durf wel te zeggen dat die functie an sich totaal niet interessant is. Daar zijn er genoeg van, en hoewel ieder deep neural net vast zijn eigen prachtige theorie en implementatie heeft, is dat niet waar het om gaat. Laad datzelfde net met nieuwe data en je krijgt iets compleet anders.
Het gaat dus om die data en niets anders. Welke data gaat erin, hoe is die samengesteld en hoe wordt geborgd dat dit een eerlijke en objectieve samenstelling is? Want dáár komt al die ellende van. Vaak is data uit beperkte bron geselecteerd, of ergens aangekocht, en in ieder geval is ‘ie niet getest op representativiteit en actualiteit. Daar gaat het dan meteen mis, want met slechte brondata ga je natuurlijk nooit goede voorspellingen doen. Maar het enge is, het lijken bij het testen best goede voorspellingen want je houdt altijd een stukje van je brondata apart om eens mee te testen. En ik geloof onmiddellijk dat je dan goede uitkomsten krijgt. Logisch, het is dezelfde bron en op dezelfde manier gecategoriseerd.
Ik zou er dus hard voor willen pleiten om geen tijd te verspillen aan die algoritmes, maar juist de problemen bij de bron te bestrijden: geen data de overheid in tenzij met keurmerk. De data moet kloppen, eerlijk zijn en volledig. Dáár een toezichthouder voor lijkt me een prima idee.
Arnoud
Ik zou me op de hele keten, van algoritme, trainingsdata, inbedding in bestaande systemen en inbedding in werkprocessen richten. Zo kan je heel makkelijk een keten creëren die met hoge kwaliteit en hoge mate van trefzekerheid gebeurtenissen uit het verleden herkent terwijl je in die situatie juist moet inspelen op onverwachte gebeurtenissen. Je kan niet oordelen over een onderdeel los van de hele keten en de context waarin die toegepast wordt.
Laat ik me er maar eens aan wagen om een voorspelling te doen: in plaats van alleen vooraf te testen of een dataset representatief is (deterministisch, statistiek….), zullen datasets alsnog ongeschikt worden betiteld indien het hiermee getrainde neurale netwerk politiek incorrecte output genereert. Ik zie ze nu al met vertwijfeling en ongeloof naar het computerscherm staren!
Training data zou onderdeel moeten zijn van het leeralgoritme. Zodoende is er bias mogelijk in:
De training data (bijvoorbeeld: Er zijn variabelen die een proxy zijn voor beschermde variabelen, zoals religie of herkomst).
De test data (bijvoorbeeld: De nieuwe data is niet IID, en heeft een compleet andere distributie, zodat de signalen die geleerd zijn tijdens trainen niet relevant zijn voor nieuwe test data)
Het model (bijvoorbeeld: een neuraal netwerk heeft geleerd om huidskleur te herkennen en neemt dit mee in de voorspelling).
De optimalizatie functie (bijvoorbeeld: Een zelfrijdende auto wordt geoptimaliseerd voor het aantal kilometers zonder auto-ongelukken, maar (bijna)-aanrijdingen met voetgangers wordt niet bestraft)
De target (bijvoorbeeld: men heeft alleen fraudeurs uit een bepaalde doelgroep verzameld, wat een algemeen fraude-model moest zijn, is meer een doelgroep+fraude detector geworden)
De beslissing (bijvoorbeeld: de voorspelling van een ziekenhuis-triage-model wordt klakkeloos overgenomen, zonder met “common sense” naar de foutenanalyse te kijken).
Verder: Machinaal leren is een subset/onderdeel van kunstmatige intelligentie (zoals algebra een onderdeel is van de wiskunde). De naam voor lerende statististische algoritmen is “probabilistische algoritmen”.
Mijn inziens is het dweilen met de kraan open: Er is hard regulatie nodig, maar water gaat waar het wil gaan, en regulatie is slechts een artificieel obstakel. Wil men dit goed doen, dan heeft met een centrale authoriteit nodig, die alles napluist en de verzoeken tot inzage geautomatiseerde beslissing behandeld. Maar ik geef op dit gebied de overheid weinig kans: Men heeft de klok gehoord, maar weet niet waar de klepel hangt.
Ik heb geen moeite met enkel het algoritme op het eind beoordelen. Dat is immers waar de beslissingen uitkomen.
Alle trainingdata heeft een beperkte houdbaarheid. Voor lang houdbare datasets een paar jaar, maar soms niet veel langer dan de houdbaarheid van een pak melk. Daarna zijn regelingen, gedrag of externe factoren zo veranderd dat de waarde nul is. Toch blijven de algoritmen die er op gebaseerd zijn veel langer in gebruik.
Je (en waarschijnlijk ook de beleidsmakers) mist een belangrijk aspect: Een statistische correlatatie bewijst geen causaal verband. Dat is een harde wet!
Je moet niet kijken naar keurmerken op data of op algoritmes of of uitkomsten, maar naar een basis-kennisniveau van beslissers, voldoende hoog om de bovenstaande universele waarheid te erkennen.
Dat is het grote probleem van democratie: 51% domme onbenullen kunnen een domme onbenul als leider tot gevolg hebben.
Correlation != Causation is een beetje een open deur. Correlatie is wat we observeren, causatie heeft altijd assumpties nodig. Je gebruikt een causaal model voor het maken van een beleid (“roken veroorzaakt longkanker, daarom reclame voor jongeren en roken verboden maken.”). Je gebruikt een correlatiemodel voor een voorspelling (“een individue met deze kenmerken heeft hoge % kans op longkanker, daarom even een check maken”).
Beslissingswetenschap bestond reeds voordat algoritmen een voorspelling deden. Als beslissingswetenschappers onbenullen zijn, dan is het hele ML vraagstuk irrelevant: men zou domme beslissingen nemen of het nu gebaseerd is op checklijstjes of de output van een model.
51% (meerderheid bepaald) is een feature van democratie, niet een bug. Democratie in vraagstelling brengen, omdat het resultaat voor jou dom, onbenullig, tegendraads, populistisch, …, is, is eng en een probleem.
Onzin. Democratie heeft altijd controles nodig om te zorgen dat er geen nare uitkomsten uit komen. Daarom moet bijvoorbeeld voor grondwetswijzigingen een twee derde meerderheid zijn. En daarom hebben we de Trias Politica uitgevonden.
Mensen die democratie als absoluut goed zien, die zijn pas eng. Ik weet zo even niet wie het zei: “Democracy is two wolves and a lamb voting on what to have for lunch.”
Controles op domme onbenulligheid? De meerderheid bepaald. Een minderheid die dan zegt “maar de meerderheid heeft ongelijk en is dom-populistisch-onrealistisch-watdanook” en dit als probleem aangeeft, dat is eng, want de enige manier om dat “recht te zetten” is om naar de minderheid te luisteren en daarmee dus de democratie aan de kant te zetten. Intelligentie als kiesdrempel is eng.
Inderdaad, dat is eng.
Maar als jij de lemming bent die denkt dat in de zee springen GEEN goed idee is, dan denk je daar wel anders over.
Democratie is ideaal, zolang iedere deelnemer rationeel is en de risico’s herkent die gepaard gaan met bepaalde keuzes. En daar schort het aan [Voorbeeld: anti-vaxxers].
Verder is natuurlijk het nadeel aan democratie dat het georganiseerd is op basis van vrij willekeurige zaken nationaliteit/geografie/leeftijd. Het is vrij willekeurig dat jij je democratische rechten alleen zinvol kunt oefenen in een groep die bestaat uit alle andere Nederlanders van 18+. Misschien voel jij je veel meer verbonden met Franse universitair opgeleiden van tussen de 25 en 40 dan met iemand uit een andere Nederlandse provincie. Maar kun je daar iets mee? Nee, je wordt, gedwongen, op een hoop gegooid met anderen waar je misschien niet veel vertrouwen in hebt. Is dat goed?
De doelstelling van democratie is een ordelijk bestuur scheppen waarin het leeuwendeel van de mensen zich kunnen vinden en ontplooien. Daarbij is “de helft plus een bepaald” een strategie om tot een soort van concensus te komen, in de zin dat men de uitkomst accepteerd. Als diezelfde helft plus een bijvoorbeeld gaat besluiten dat alle kaalhoofdigen dood moeten, dan zal ik dat niet accepteren (zelfs als alle niet kaalhoofdigen het daar unaniem over eens zijn), en mij, desnoods met geweld, tegen verzetten. Daarmee is dus de het ordelijk bestuur en dus democratie ten einde gekomen.
Thorvald, lees het verhaal van Arnoud nog eens. Het gaat over geautomatiseerde besluitvorming op basis van statistiek. En daar zit meteen het probleem.
Jij, slimme persoon, gebruikt een causaal model voor het maken van een beleid en een correlatiemodel voor een voorspelling. Prima, goed, applaus. Maar de beleidsmakers doen dat blijkbaar niet, volgens de blog van Arnoud, en dat is zeer zorgelijk.
Wat heeft een keurmerk op data of algoritme, of beide, voor zin, als de verantwoordelijken niet diep doortrokken zijn van de waarheid: Correlation != Causation?
Wat ik mij afvraag is hoe de overheid omgaat met personen die algoritmisch correleren met een hoge risicofactor, terwijl ze geen risico zijn. We hebben nu een rel rond de kinderopvangtoeslag waarbij de belastingdienst overhaast (gebaseerd op etnisch profileren?) een toeslag heeft stopgezet en daarmee gezinnen in financiële problemen heeft gebracht.
Het opwerpen van drempels voor “risicogroepen” vergroot de marginalisering van deze groepen. Het niet (tijdig) krijgen van (een voorschot op) een uitkering creëert financiële problemen. Als andere groepen het geld wel tijdig krijgen dan levert dat fricties op.
Een ander risico is selectief alleen personen uit hoge risicoklassen aan extra controles onderwerpen. Naast de sociale frictie die dat oplevert, is er ook het risico van algoritmische tunnelvisie. Omdat de risicogroepen extra gecontroleerd worden, wordt er meer fraude ontdekt, waardoor het systeem de risico’s hoger blijft inschatten. Tegelijkertijd kunnen personen uit “laag-risicogroepen” ongecontroleerd frauderen.
Gelukkig heb ik geleerd dat als er “herhalen” staat zonder opgave van het aantal herhalingen, het dan een enkelvoudige herhaling is en niet een oneindige herhaling. Anders stond ik nog steeds onder de douche… 😀
Maar het gaat uiteindelijk om de data en hoe deze is verzameld. Maar ook belangrijk vind ik wat de algoritmes op basis van deze data kunnen concluderen. Ik herinner nog steeds die kwestie van een supermarkt in de US die advertenties voor zwangerschapsproducten en babykleding stuurde naar een tienermeisje. Vader boos, want haar “maagdelijke” dochter was nog niet aan kinderen toe en de supermarkt bood hun verontschuldigingen aan. Alleen, de algoritmes bleken te kloppen want het meisje bleek zwanger op dat moment en het algoritme had dit kunnen bepalen op basis van haar zoekgedrag…
Dus niet alleen de data die erin gaat moet aan controles worden onderworpen, maar ook de data die er vervolgens uit komt. Want als een algoritme goed werkt, wat kan deze dan vertellen over mensen in de toekomst?