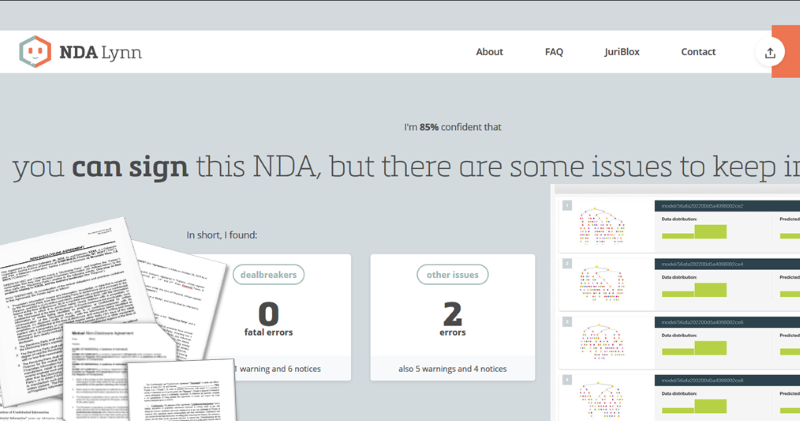
Heb jij ook wel eens gedroomd van een robot die je werk overneemt? Nou ik wel, want ik was het reviewen van geheimhoudingscontracten (NDA’s) ondertussen méér dan zat. Steeds maar ongeveer dezelfde teksten van ongeveer hetzelfde commentaar voorzien en opletten dat dezelfde stomme valkuilen er niet weer in zitten. Dat moet toch automatisch kunnen, leek me. Dit soort documenten is immers zó standaard opgesteld. En omdat ik ook nog ooit iets met informatica had gedaan, besloot ik zelf met haar aan de slag te gaan. In oktober 2017, na ruim een jaar bouwen, lanceerde ik deze lawyerbot, en ik noemde haar NDA Lynn. En nu, bijna drie jaar later, werken we aan de gaafste feature die ik ken: Edit Mode. Lees mee in deze X-delige serie hoe we van daar naar hier kwamen.
Ik weet niet meer precies wanneer ik kwam op het idee van Lynn. Maar het lezen en becommentariëren van al die NDA’s was ik al jaren zat. Ik doe het ook al een kleine twintig jaar. Eerst bijna tien jaar bij Philips, daarna (sinds 2008) als partner bij ICTRecht. Ik schat dat ik meer dan drieduizend NDA’s heb gereviewd in die tijd. En altijd was het verhaal ongeveer hetzelfde, want op hoe veel manieren kún je nu eenmaal zeggen dat je informatie gaat delen die je dan geheim moet houden, met geschillen te behandelen in Amsterdam en geen garantie op de juistheid van de informatie.
Ik weet nog wel dat ik op zeker moment drie NDA’s van drie klanten op één dag deed. Volledig ongerelateerd alle drie, maar de teksten kwamen grotendeels overeen. Toen ging het dus knagen: zou dat te automatiseren zijn? Het is in feite alleen maar tekstvergelijking, iets waar computers veel beter in zijn dan ik. Maar het gaat wel een stapje verder dan alléén maar het bekijken of twee alinea’s grofweg dezelfde tekens bevatten.
De hype rond AI en machine learning was toen al aardig op gang. Zou het met bijvoorbeeld Google of Microsoft’s cloudbased machine learning systemen kunnen? Het zag er allemaal veelbelovend uit, maar er was één groot nadeel. There is no cloud, it’s just someone else’s computer. Ik zag het niet zitten om voor deze dienst afhankelijk te zijn van een online service van een ander, ook niet als die gratis was.
Toen kwam ik het Spaanse BigML tegen. Een sympathieke dienst, een API die je meteen een goed gevoel geeft én de mogelijkheid om ML modellen offline in te zetten. Dus gewoon zeg maar een executable op je eigen server, zodat het niet uitmaakt of hun dienst beschikbaar is of niet. Dat was precies wat ik nodig had.
Hier, het resultaat van een avondje prutsen (ja, in PHP, dat was het makkelijkste) om eens te zien hoe dat nu werkt, zo’n machine learning systeem:
do {
$res = bigML("poll", $bpid);
if (isset($res["status"]["code"])) {
if ($res["status"]["code"] != $oldstatus) {
echo "\n => ".$res["status"]["message"];
$oldstatus = $res["status"]["code"];
} else
echo ".";
} else
print_r($res);
if ($i > 0) sleep(1); $i++;
} while (($res["status"]["code"] != "5") && ($i <= 10));
Het werkte prachtig. Alleen: een machine learning systeem is niets zonder data. In mijn geval dus NDA’s. Hoe kom je daar nou aan?
Een geluk aan de NDA is dat hij zo wijdverspreid is dat je er met gemak een paar honderd op internet vindt. Dat is dus het eerste dat ik deed. Daarnaast had ik er zelf natuurlijk een heleboel, alleen die had ik voor klanten geschreven of gelezen en dan kun je dus niet zomaar die in je eigen systeem stoppen. Later, met Lynn al draaiende, zou dat geen probleem meer zijn: Lynn is gratis maar je moet me toestemming geven je NDA te gebruiken voor verbetering van de dienst. Ik heb er nu een dikke 5000. Maar in het begin was het een serieuze uitdaging om de juiste NDA’s te vinden. Daarover een volgende keer meer.
Het basisidee van Lynn is vrij rechttoe rechtaan. Je krijgt een NDA, je extraheert de tekst, je kijkt welke clausules er zijn en zegt voor iedere clausule of deze acceptabel is of niet. Er zijn tools genoeg die een geupload document kunnen converteren naar tekst, en genoeg libraries ook voor tekstmanipulatie op zich. En als je weet wat voor clausule je hebt, kun je gewoon in een tabel kijken of hij acceptabel is of niet. Maar hoe weet je nu wat voor clausule je hebt?
Machine Learning (ML) is een vorm van AI waarbij een grote hoeveelheid data wordt geanalyseerd op gemeenschappelijke onderscheidende kenmerken. Hiermee maakt het systeem een functie die grofweg zegt of iets categorie A, B of C is. Als je dan een nieuwe input hebt (in mijn geval dus een nieuwe clausule) dan kijkt het systeem met die functie in welke categorie het hoort.
Dat betekent dus dat ik een dataset moet maken die een paar honderd NDA clausules bevat. En van elke clausule heb ik diverse smaakjes nodig, zeg maar wat is een strenge beveiligingsclausule en welke is juist lekker relaxed. Dan kan een ML systeem gegeven een inputclausule zeggen of deze het meest lijkt op een strenge beveiligingsclausule of juist eerder een rechtskeuze voor Florida. En als ik dat heb, kan ik een advies uit mijn tabel halen.
Dan het volgende probleem: hoe vind je nu precies een clausule? Na een stuk of dertig NDA’s te hebben bekeken, kom ik tot de conclusie dat daar geen standaardmanier voor is. Iedereen groepeert teksten op zijn eigen manier. Soms zijn het keurig genummerde alinea’s, anderen doen een opsommingslijstje en weer anderen maken gewoon een lap tekst met willekeurig een enter hier en daar.
En dan heb je ook nog grapjassen die verderop nog even terugkomen op een onderwerp. Zo zie ik die beveiligingseisen op drie of vier plekken in het document staan, zodat je niet eens kunt spreken van een beveiligingsclausule. Of er wordt op allerlei plekken geroepen dat er aansprakelijkheid is voor X of Y.
Nee, er zit niets anders op. Niet kijken naar clausules, je hebt alleen zinnen. Dat betekent dus, extraheer de zinnen uit het document, label die met hun onderwerp en voeg alles samen dat hetzelfde onderwerp is. Dat is dan je “clausule”, en daar kun je dan een kwalificatie op doen hoe streng of relaxed die is.
Zoals je hieronder ziet, krijg je dan een systeem waarbij je twéé machine learning componenten inzet. Het eerste zegt van een zin welke categorie het is (het 1st stage model) en het tweede systeem zegt van alle zinnen uit één categorie welk smaakje daaraan te geven is (het 2nd stage model). Gelukkig zijn ML systemen razendsnel, zeker de offline modellen die BigML kan aanbieden. Want je wil echt niet per zin een aanvraag doen bij de systemen van Google of Microsoft en dan een seconde wachten op het antwoord.
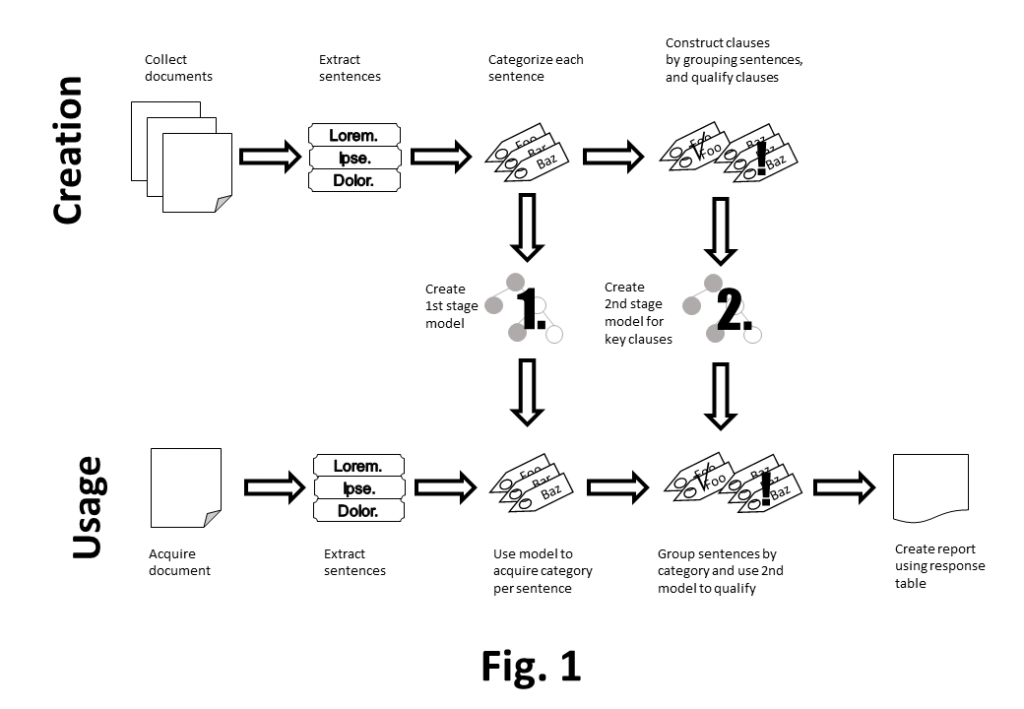
Deze architectuur ziet er goed uit. Hij heeft alleen één groot nadeel: ik moet nu niet langer een paar honderd clausules van een labeltje voorzien, maar een dikke duizend zinnen. Want elke clausule telt een zin of vijf, zo ontdek ik al snel. En als ik dat heb gedaan, dan moet ik daarna ook nog eens de zinnen van dezelfde clausule bij elkaar vegen en daar weer een labeltje op plakken dat me vertelt welke smaak de clausule is.
En hoe ik daarmee aan de slag ging, dat vertel ik morgen.
(Dit is het eerste van vijf vakantieberichten.)
Arnoud
Interessant zo’n kijkje in de keuken!
Vraagje: de NDA’s die Lynn voorbij ziet komen, worden die automatisch gebruikt voor training of zit daar nog een handmatige bewerking/selectie tussen? Reden voor de vraag: als mensen Lynn gebruiken om hun NDA te ‘ontwerpen’ en misschien wel 10 maal achter elkaar een telkens iets aangepaste versie inschieten, gaat dat dan een automatisch trainingsproces verstoren? Of heb je een aparte ML die de set voor training eerst opschoont?
Ik review dat handmatig. Ik selecteer de nda’s met slechte performance en corrigeer handmatig alle classificaties daaruit. Periodiek voer ik dat in de dataset terug.
Ik zie inderdaad wel dat uitproberen maar voor Lynn maakt dat weinig uit. Classificatie is classificatie. Waar zou ik me zorgen over moeten maken?
Maar hoe weet je welke er een slechte performance hebben? Als je alleen stukken handmatig behandeld waar Lynn niet mee overweg kan, dan weet je nog steeds niet of hij correct omgaat met de stukken die hij wel afhandeld.
Goed punt. Ik ga uit van de betrouwbaarheid die Lynn zelf meldt bij haar predictie. Ik heb gemerkt dat als die boven de 80% is, hij eigenlijk altijd klopt. Ik check dat af en toe maar zie geen afwijkingen.
NDA’s zijn niet mijn ding, maar het is interessant om eens te lezen hoe dit werkt. Leuk! Weer eens anders dan katten van honden scheiden :).
Ik las net de FAQ, en wellicht dat je er een andere ML (Google Translate) over mag laten gaan. De tekst bij het Nederlandse antwoord op de vraag “Hoe accuraat ben je?” komt niet overeen met de Engelse tekst: Er staat 83.21 ipv 87.21 genoemd; er staat een overbodige punt achter “F1”, en (persoonlijke ergernis), percentages (“86”) en delen (0.86) worden beiden in dezelfde paragraaf gebruikt. Mijn OCD wenst consistentie 😉
Erg leuk dat je dit traject zo deelt, de oldschool PHP code is een kers op de taart.
Ik ben benieuwd waar je break-even punt lag op tijdsbesteding /kosten: bij hoeveel NDA’s heb je de investering eruit en begint de schoorsteen te roken?
Deze oplossing wint het natuurlijk sowieso op de variabele “werkplezier” dus laten we die even buiten beschouwing laten.
Super cool! Ik vind vooral je tweestappenopzet creatief. Wel erg arbeidsintensief, maar als het je uiteindelijk tijd bespaart, natuurlijk alle moeite waard.
Ik denk dat @Jeroen Boschma zich afvraagt of zo’n ML-systeem realtime leert. Dus of elk document wat je laat checken, ook input is voor de training. Dat is niet het geval. De training is een los proces, met een vooraf bepaalde hoeveelheid en kwaliteit input. Uit die training rolt een statisch model (een bestand) en aan de hand daarvan worden nieuwe documenten gecheckt. Als je die nieuwe documenten wilt meenemen in het model, zal je de training opnieuw moeten uitvoeren met de nieuwe documenten toegevoegd als input.
Op die manier. Nee, realtime leren is volgens mij zelden tot nooit aan de orde. Alleen als je een direct meetbare objectieve waarheid hebt, dan kun je realtime aanpassen. Denk aan inparkeren met een autonome auto: je kunt objectief vaststellen waar je moet stilstaan, en wanneer je verkeerd gaat (afstand tot andere auto’s kleiner dan 15 centimeter). Dan kun je met correctiefactoren (slippende remmen, gladde ondergrond) gaan spelen om eerder stil te staan et cetera.
Realtime leren is zat aan de orde, moet je zien hoe snel je realtime leert als je je vingers in het vuur steekt, of een muizenklem op je vingers krijgt een stomp op je oog krijgt. Realtime onmidelijke actie
Of heb ik hier weer een juristen woordenboek nodig, maar ja ik heb al vaker meegemaakt in de praktijk dat juristen en vooral ambtenaren van een nee ja kunnen maken. Vandaar ook dat ik hier meedoe om de kunst af te kijken
We hebben het over artificial intelligence, niet over mensen.