 De Verkeersinformatiedienst (VID) volgt al jarenlang de bewegingen van miljoenen auto’s op de weg. Deze data zijn geen persoonsgegevens en niet herleidbaar, stelt het bedrijf, maar dat is dubbel onjuist. Dat meldde Computerworld onlangs, op basis van mijn antwoord dat “Hashing is absoluut een privacyvriendelijke oplossing, maar daarmee blijven de data nog steeds persoonsgegevens, ze zijn immers niet onherleidbaar geanonimiseerd”. Maar, zo mailden veel mensen me: een hash is toch niet meer tot een persoon te herleiden, je weet niet meer wie het is, hoezo is het dan nog steeds een persoonsgegeven?
De Verkeersinformatiedienst (VID) volgt al jarenlang de bewegingen van miljoenen auto’s op de weg. Deze data zijn geen persoonsgegevens en niet herleidbaar, stelt het bedrijf, maar dat is dubbel onjuist. Dat meldde Computerworld onlangs, op basis van mijn antwoord dat “Hashing is absoluut een privacyvriendelijke oplossing, maar daarmee blijven de data nog steeds persoonsgegevens, ze zijn immers niet onherleidbaar geanonimiseerd”. Maar, zo mailden veel mensen me: een hash is toch niet meer tot een persoon te herleiden, je weet niet meer wie het is, hoezo is het dan nog steeds een persoonsgegeven?
Vaak wordt gedacht dat een gegeven pas een persoonsgegeven is als je weet om wie het gaat. Er zou een naam of contactgegevens nodig zijn, en zolang je die maar niet hebt, zou er niets aan de hand zijn. Dit is echter onjuist en wel hierom, zoals dat heet.
Een persoonsgegeven is volgens de wet een gegeven dat direct of indirect tot een persoon te herleiden. Als je iemands naam of contactgegevens hebt, dan heet dat “direct herleidbaar”. Maar heb je die niet, maar zegt wat je hebt wel iets over een persoon, dan is het indirect identificeerbaar en dus alsnog een persoonsgegeven. “Die man met de hoed daar achterin” is dus net zo goed een persoonsgegeven als “Wim ten Brink”.
Ik vind dat niet meer dan logisch: een naam is niet perse een groter privacyprobleem dan een IP-adres. Sterker nog, ik denk dat ik vaker gevolgd/gemonitord wordt via mijn IP-adres dan via mijn voor- en achternaam. En de regels over persoonsgegevens zijn gemaakt om te zorgen dat dergelijke privacyproblemen verminderd worden. “Geen naam = geen persoongegeven” zou dan een maas in de wet zijn waar een Google Modular Data Center doorheen kan.
De Artikel 29-werkgroep, het samenwerkingsverband van privacytoezichthouders, heeft dit al in 2007 gesignaleerd in haar Advies over het begrip ‘persoonsgegeven’. In de context van medisch onderzoek worden patiëntgegevens vaak gepseudonimiseerd (“patiënt X123”), maar dat is niet genoeg: dat gegeven gaat over één patiënt en is dus nog steeds een persoonsgegeven. Althans, als het redelijkerwijs mogelijk is om die gegevens terug te herleiden:
Zijn de gebruikte codes uniek voor elke persoon, dan doet het risico van identificatie zich voor als het mogelijk is de encryptiesleutel te achterhalen. Het risico dat de systemen door een buitenstaander worden gekraakt, de waarschijnlijkheid dat iemand binnen de organisatie van de verzender (ondanks het beroepsgeheim) de sleutel ter beschikking stelt en de haalbaarheid van indirecte identificatie zijn dus allemaal factoren waarmee rekening moet worden gehouden om te bepalen of de betrokkenen kunnen worden geïdentificeerd met alle middelen waarvan mag worden aangenomen dat zij redelijkerwijs door degene die voor de verwerking verantwoordelijk is dan wel door enig ander persoon in te zetten zijn, en of de informatie dus als “persoonsgegevens” moet worden beschouwd.
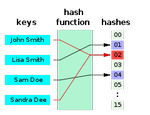
Een hash functie is ook een “encryptie” in de zin van deze analyse. Een hash is weliswaar niet omkeerbaar, maar je kunt wel met een nieuwe invoer kijken of deze dezelfde hash geeft. Dus het probleem is hetzelfde.
Zoals het Cbp het zegt in haar richtsnoeren beveiliging van persoonsgegevens:
Het toepassen van cryptografische bewerkingen op identificerende gegevens leidt op zichzelf tot pseudonimisering (het identificerende gegeven wordt vervangen door een ander identificerend gegeven) en niet tot anonimisering (de gegevens worden omgezet naar “een vorm die identificatie van de betrokkene feitelijk niet langer mogelijk maakt”84[1]).
Dit betekent dus dat persoonsgegevens hashen er niet voor zorgt dat je onder de Wbp uit komt.
Maar er is een sprankje hoop: dat je onder de Wbp valt, wil niet zeggen dat je dus toestemming moet vragen aan iedereen. Er is die uitzondering voor de eigen dringende noodzaak, en daarbij moet je een afweging maken of de privacy van de betrokkenen zwaarder weegt of niet dan jouw noodzaak. Onderdeel van die afweging is hoe makkelijk of moeilijk het is om mensen te identificeren (direct of indirect). Dus als je werkt met hashes dan zit je eerder aan de goede kant dan wanneer je met blote IP-adressen of e-mailadressen gaat werken.
Wél zit je vast aan alle andere regels uit de Wbp, zoals het moeten geven van inzage, het uitleggen wat je doet en het omgaan met een verwijderverzoek.
Arnoud
Interessant: ik zit in het medisch onderzoek, en bij het publiceren van bepaalde onderzoeksresultaten eist het wetenschappelijk tijdschrift dat de ruwe data publiekelijk beschikbaar moeten zijn. Dit zodat andere onderzoeksgroepen de resultaten kunnen verifiëren. De toestemming voor gebruik van het weefsel van patient is vereist binnen het instituut, en we zorgen er natuurlijk voor dat er slechts een verzonnen persoonsnummer bij de ruwe data staat, maar ik realiseerde me niet dat het volgens de wet dus nog steeds een persoonsgegeven is.
Een verzonnen persoonsnummer is geen persoonsgegeven, behalve als je het zo ‘verzint’ dat je achteraf bij diezelfde persoon weer hetzelfde nummer kunt terugvinden. Dus als je gewoon willekeurige nummers verzint (en je houdt niet bij welke personen welk nummer krijgen) dan is er niks aan de hand.
Zelfs als je tijdens het onderzoek bijhoudt wie welk nummer heeft, hoef je achteraf alleen maar die database met persoon+nummer te vernietigen, en dan zijn het in principe geen persoonsgegevens meer.
Correct, behalve in uitzonderlijke gevallen waarin mensen aan de hand van de resterende data al identificeerbaar zijn. Een voorbeeld is foto’s van psoriasis en andere huidaandoeningen: tatoeages, moedervlekken of zelfs maar oorringen kunnen al tot identificatie leiden zelfs als je de namen weglaat (bron).
Maar die database is er dus wel, en met reden. Dezelfde experimentele gegevens kunnen meermalen gebruikt worden om de voortschrijdende klinische situatie opnieuw te analyseren. Of mogelijk blijkt uit later onderzoek (eventueel van anderen) dat een bepaalde medische of experimentele factor van belang is, die we zelf niet bekeken hadden. We kunnen dan achteraf dit onderzoeken. Die database is natuurlijk wel beperkt toegankelijk voor slechts een paar mensen, maar daarmee is dat verzonnen nummer als ik het goed begrijp dus wel een wettelijk persoonsgegeven.
en van wie krijgen ze die toestemming voor gebruik van dat weefsel dan? Dat mag toch alleen de betreffende patiënt geven? het bevat immers ZIJN/HAAR persoonsgegevens? of geeft de patiënt van te voren aan dat weefsel e. d. voor onderzoek mag worden gebruikt?
Bij ons instituut is dat de gang van zaken; patiënten worden vooraf geïnformeerd en gevraagd of het eventuele restmateriaal (veel weefsel gaat al ‘op’ aan de diagnose) gebruikt mag worden voor wetenschappelijk onderzoek.
Dan ben ik wel benieuwd welke persoonsgegevens van reageerders en bezoekers op dit blog worden opgeslagen, op welke manier ze worden opgeslagen, hoe lang, welke partijen potentieel toegang hebben tot die gegevens (incl. hosting-providers en overheden), enzovoort.
Naam, e-mailadres, URL (indien opgegeven), IP-adres, tijdstip van reactie. In de WordPress database, welke is beveiligd zoals alle WordPress sites en databases. Dit blijft bewaard totdat de reactie wordt verwijderd of deze blog wordt opgeheven (bij benadering is dat 1-1-2099). Ik heb daar toegang toe, mijn hoster kan er theoretisch ook bij maar mag dat contractueel niet zonder toestemming of dringende noodzaak. Justitie kan erbij en volgens mij zelfs zonder bevel officier, want het zou gaan om “administratieve kenmerken” in de zin van 126nc Strafvordering en dat vereist alleen een verdenking van een misdrijf. Verder kan Google en collega’s, eigenlijk de hele wereld, bij alle gegevens behalve e-mailadres en IP-adres.
Is er een noodzaak voor het opslaan van IP-adres en e-mailadres?
Ik merk dat je e-mailadres gebruikt voor identificatie van regelmatige reageerders, zodat die niet hoeven te wachten op handmatige controle van posts (een verkapt wachtwoord dus). In principe zou je die toch wel na, zeg maar, zo’n 2 jaar van inactiviteit wel kunnen verwijderen? En, ze zouden gehasht opgeslagen kunnen worden, tenzij je reageerders wilt kunnen e-mailen(*).
IP-adres zou nuttig kunnen zijn om bij echt ernstig misbruik achter de daders aan te kunnen gaan, maar als je bijna elke dag de site controleert, dan zou je ook na een week wel de IP-adresgegevens kunnen verwijderen.
Wat betreft de andere gegevens: dat is duidelijk, want die worden gewoon zichtbaar op de site.
(*) In theorie zou je je site ingewikkelder kunnen maken met een vinkje “ja ik wil ge-e-maild kunnen worden”. In de praktijk bestaat die keuze ook al zonder vinkje: je kunt gewoon een fake e-mailadres invullen.
Het IP-adres wordt op dit moment (onder andere) gebruikt zodat je 15 minuten na het plaatsen van een reactie deze nog aan kan passen. Dat dat zou ook met een sessie-cookie kunnen, maar de software die Arnoud nu gebruikt doet het nu eenmaal op deze manier. En ja, het is bekend dat dat betekent dat een collega/iemand die jouw internetverbinding deelt jouw reactie kan wijzigen.
Voor e-mail adressen kan ik mij dit voorstellen maar in het geval van IP adressen biedt hashing nauwelijks een drempel. Wanneer men weet dat de hash een IPv4 adres betreft, biedt deze slechts minder dan 32 bit entropy, vergelijkbaar met een wachtwoord van 4 tekens en kraakbaar in luttele seconden. (https://xkcd.com/936/, al gebruik ik een iets andere definitie van de bits)
Zoals Tim hierboven al aankaart is dat eerder een belediging voor jezelf dan een bewijs dat je de privacy van je bezoekers waarborgt 😛 Deze informatie is ook tamelijk nutteloos zonder kennis van het patchbeleid en overige beveiligingsmaatregelen van jouw en je hostingprovider. Overigens kan ik als bezoeker niet verwachten dat je deze informatie beschikbaar stelt, het is dan als bezoeker ook verstandig aan te nemen dat dergelijke informatie (ip, e-mail adres en url in dit geval) semi publiek beschikbaar zijn.Sinds wanneer zijn IP-adressen persoonsgegevens?
“Dient artikel 2, onder a), van richtlijn 95/46/EG van het Europees Parlement en de Raad van 24 oktober 1995 betreffende de bescherming van natuurlijke personen in verband met de verwerking van persoonsgegevens en betreffende het vrije verkeer van die gegevens aldus te worden uitgelegd dat een internetprotocoladres (IP-adres) dat een aanbieder van diensten in verband met de toegang tot zijn internetsite opslaat, voor deze aanbieder reeds dan een persoonsgegeven vormt, wanneer een derde (in casu: de aanbieder van de toegang) beschikt over de bijkomende kennis die nodig is om de betrokken persoon te identificeren?” (C-582/14, voorgelegd aan het HvJ EU maar nog niet beantwoord)
Ik durf alvast wel te stellen dat gehashte MAC-adressen geen persoonsgegevens zijn.
Om datasets anoniem te maken is hashing vaak niet afdoende. Overheidsinstellingen die data delen met bijvoorbeeld het Centraal Bureau voor de Statistiek gebruiken geen hashing, maar ID’s. Als een IP adres in rij 5 voor het eerst gezien wordt, dan krijgt deze bijvoorbeeld de ID 5. Om dan terug te rekenen van ID naar IP heb je de volgorde van de originele database nodig.
Hashing is vaak gemakkelijker te reverse engineeren. Vooral als men MD5 en een zwakke salt gebruikt om IP’s te hashen. De input-space is dan zeer beperkt en het kraken gaat sneller.
Daarnaast kan men bij beide hashes en ID’s aan het aantal keer voorkomen uitrekenen wat voor woord, naam of IP daar achter zit. Stel een IP is enorm goed gehashed of ID’ed, maar het komt onevenredig vaak voor, dan is dit waarschijnlijk het IP van Googlebot. Indien met hashes is gewerkt dan kan deze informatie gebruikt worden om direct de salt te kraken en alle overige IP’s te kraken. Ik heb met zwak-geanonimiseerde click datasets gewerkt waar het land van herkomst en het IP op deze manier te achterhalen waren.
Als laatste noot: Zelfs anonieme datasets zonder persoonsgegevens zijn soms naar personen herleidbaar. Zo publiceerde AOL per ongeluk een dataset met zoekmachine-opdrachten voor de wetenschap. Een aantal personen was helaas direct herleidbaar, omdat ze op locaties, namen en bedrijven hadden gezocht. Ook hun meer privacy-gevoelige opdrachten, zoals vragen over ziektes, konden dan gekoppeld worden. Het is daarom beter om op hoger geaggregeerd niveau data op te slaan, en deze detail-data zo veel mogelijk te vermijden. http://news.cnet.com/2100-1030_3-6103098.html
Overigens lijkt mij het proces van hashing/anonimisering een duidelijke verwerking van persoonsgegevens. Dat dit later als “niet-persoons”-gegeven ergens wordt opgeslagen is dan een stapje verder. Die vorm maakt nog niet dat je geen persoonsgegevens verwerkt.
P.S.: De beveiliging voor WordPress Core is enorm goed. Natuurlijk worden populaire CMS’en vaker aangevallen en zijn er meer ogen bezig om security bugs te vinden, maar WordPress Core up-to-date is zeer lastig te hacken. http://www.openwall.com/phpass/ De beveiliging kan wel beter, zoals bijvoorbeeld alleen vertrouwelijke IPs toelaten op het admin-gedeelte, maar hier zijn goede plug-ins voor. WordPress Security is geen lachertje. Drupal gebruikt hetzelfde hashing mechanisme en dat is een populair pakket voor de Nederlandse overheid, dus als je ergens gaten in kan schieten, ik denk dat de overheid geinteresseerd is.
Voor de leuk: Is een dataset met hersengolven een persoonsgegeven? De metingen en resoluties worden steeds beter, men is op dit moment op het punt dat met kan voorspellen waar iemand aan denkt.
“Facebook would like to access your heart rate. [Cancel] [Ok]” https://pbs.twimg.com/media/CDZKdYJXIAE0z4_.jpg
Als je inderdaad iets zinnigs uit die hersengolven kunt afleiden én de gegevens zijn gelinkt aan een persoon, dan zijn het persoonsgegevens.
Ik heb nu ook het Computerworld-artikel gelezen.
Het gehashte MAC-adres is op zichzelf niet heel interessant, maar dat het gelinkt is aan verkeersgegevens wel. De vraag is eigenlijk of die verkeersgegevens persoonsgegevens zijn door te zijn gelinkt aan het gehashte MAC adres.
Mijn antwoord is nee. De verwerker van de gegevens weet niet bij wie een bepaald MAC adres hoort en kan dat ook niet op een eenvoudige manier te weten komen. Zelfs ongehasht zie ik hier geen probleem.
Dat de politie nu en dan met een MAC adres langskomt waarvan de politie weet bij wie het hoort maakt de situatie niet anders. De politie is dan de gegevensverwerker, niet de VID.
Mijn antwoord is ja. Het gaat, zoals boven reeds opgemerkt, om de vraag van unieke identificeerbaarheid. Niet of er al dan niet een naam aan geplakt kan worden. MAC-adressen zijn in het onderhavige geval anoniem in de letterlijke betekenis van ‘naamloos’. Maar tegelijk zijn er wel degelijk unieke, zij het naamloze, gebruikers mee te identificeren. Dat maakt ze persoonsgegevens.
Het is denk ik zelfs andersom. Hoeveel IP adressen van 154.184.56.3 zijn er en hoeveel personen die “Piet Janssen” heten?