De beslissing van bibliotheekorganisatie NBD Biblion om boekrecensies voortaan uitsluitend te laten produceren door AI leidt tot heftige reacties. Dat las ik in tijdschrift Neerlandistiek. Niet in het minst omdat de 700 menselijke recensenten nogal onverwacht met ontslag werden gestuurd, maar ook omdat het voelt als een verschraling: de handgeschreven recensies in bloemrijke taal worden nu vier schuifjes: activiteit (van relax naar concentratie); stemming (van vrolijk naar duister); seks (van geen naar veel); geweld (van geen naar veel). Wie wordt daar blij van?
Wie een paar voorbeelden wil: klik hier. De achterliggende boosheid lijkt met name op de gedachte te rusten dat het recenseren van boeken toch een zuiver menselijke activiteit is, die je niet aan een robot/AI kunt overlaten. Het raakt aan de fundamentele discussie of een AI nu wel of niet goed een tekstanalyse kan maken.
Een aantal lezers vroeg me dan ook, geldt ditzelfde niet ook voor jouw contractenrobot? Niet helemaal, denk ik. Bij analyseren van een zakelijke tekst zoals een contract zoek je naar concreet wat er staat. Welke looptijd heeft dit, wordt hier AVG compliant afgesproken, wat is het plafond qua aansprakelijkheid. Daar zit natuurlijk een stukje interpretatie in (denk aan “hoe streng zijn de security-eisen”) maar dat gaat op een vaste manier, en je kunt dat meten.
Een boekrecensie is naar zijn aard een stuk persoonlijker. Zoals ze bij Neerlandistiek schrijven:
Presteert een groep van om en nabij de zevenhonderd mensen beter dan een paar digitale bots die boeken beschrijven? In de zevenhonderd menselijke hoofden in deze groep zitten allerlei cultureel bepaalde aannames over wat een goed geschreven boek is. Er zitten ook allerlei subjectieve meningen in over welke onderwerpen belangrijk en interessant zijn, over welke verhalen saai zijn, wat cliché-beeldspraak is en over wat een mooie stijl is.Het laat wel zien hoe moeilijk het dan is om uit zo’n dataset de relevante informatie te halen waarmee je goede uitspraken kunt doen. Bij Tzum citeren ze bijvoorbeeld het boek Alexandra:
De computer vindt dat er niet heel veel geweld in Aleksandra voorkomt en je vraagt je af hoe de computer de communistische terreur, de Tweede Wereldoorlog, de oorlog op de Krim met plunderingen en moorden beoordeelt met een schuifje bij geweld dat in het midden staat.Het gevaar dat hier achter zit, is dat het systeem getraind is op boeken waarbij geweld een heel andere rol speelt, denk aan Scandinavische moord-detectives. Dan is een verhaal met als achtergrond de oorlog op de Krim niet zo gewelddadig inderdaad.
Het zou een mooie case zijn, zoals ze bij Neerlandistiek bepleiten, om dit algoritme eens helemaal door te lichten. Op welke data is getraind, hoe zijn de labels tot stand gekomen, hoe worden uitkomsten periodiek bijgesteld? Omdat het om boeken gaat, is daarbij geen AVG-risico (zoals vaak bij AI het probleem is).
Arnoud
Het lijkt me veel beter om naar de output te kijken, oftewel, wat is de kwaliteit van de AI ten opzichte van menselijke recensenten? Op welk vlak maakt AI fouten en is de verwachting dat daar in de toekomst verbeteringen op mogelijk zijn? Kan de AI onacceptabele fouten maken (bv een verkeerd leeftijdsadvies)? En dat op basis van honderden uitkomsten, niet enkele afwijkende voorbeelden.
En volgens mij wordt daar een verkeerde aanname gedaan, namelijk dat je uit de recensie moet kunnen afleiden dat het een goed geschreven boek is. Het gaat hier niet om een recensie in een krant of tijdschrift o.i.d., het gaat over een bibliotheekorganisatie.Mi. net iets te vroeg nog voor 1 aprilgrappen, maar zou TOC|H kunnen natuurlijk…
(Ik zie overigens die schuifjes minder als recensie dan als categorisatie/classificatie)
Klinkt als geen review maar een eerste duiding van het soort inhoud, om op te filteren. En daar geen mensen voor aan het werk zetten lijkt me helemaal prima. Ook als er soms een foutje wordt gemaakt, dat vast kan worden gecorrigeerd als het soms niet klopt.
Fouten zullen ook door mensen gebeuren. En zowel mensen als botjes kunnen leren.
Biografie of non-fictie waar nog levende mensen worden besproken?
De schuifjes zijn extra, maar het is óók een recensie in gewoon geschreven Nederlands. Zie dit voorbeeld van Tzumz: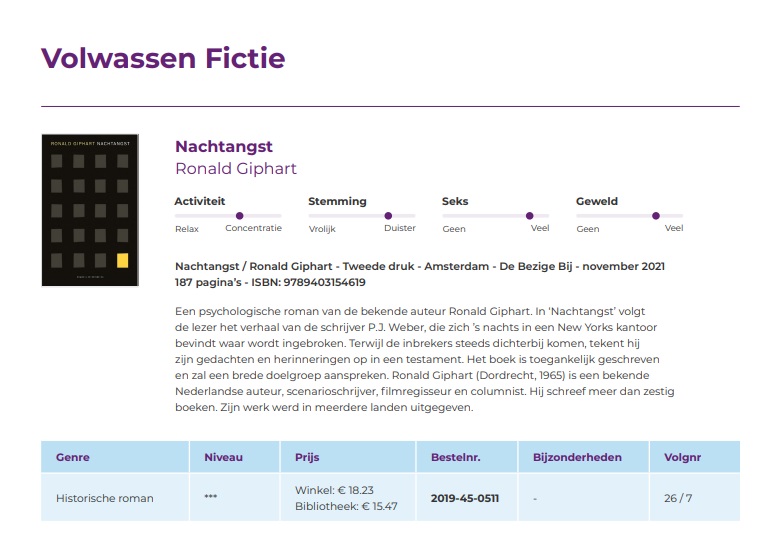
Die AI zal al gauw merken, Ronald Giphart = seks. Totdat de beste man eens een kinderboek voor achtjarigen schrijft, kun je je AI meteen bij het vuil zetten.
Dan begrijp je niet hoe AI werkt. AI heeft geen geheugen voor data dat het verwerkt en doet ook geen veronderstellingen. Een nieuwe tekst (data) wordt gescand en telkens opnieuw door het model “beoordeeld”. Van enige vooroordeel kan dus geen sprake zijn.
..dat hangt helemaal af van de trainingsdataset. Als daar toevallig al veel boeken van Giphart in zitten dan kan dit vooroordeel best eens uit de trainingsdata komen. Het is een misverstand om te denken dat AI (meer bepaald ‘machine learning’ en/of ‘deep learning’) geen bias kan hebben. Arnoud heeft al in 2018 daar een leuke blogpost over geschreven. Ook deze, meer specifiek de tweede reactie onder het artikel, illustreert in mijn ogen erg goed hoe een AI tot volledig onverwachtte resultaten kan komen op basis van een onbedoeld en niet door de makers herkend vooroordeel in de trainingsdata.
Soms gaat de output van een AI (na validatie uiteraard) zelfs als trainingsdata terug het algoritme in zodat AI kan leren van zijn eigen fouten en zijn eigen succesen. Dat zou je in mijn ogen zelfs mogen interpreteren als ‘de AI heeft geheugen’
Wow best imposante samenvatting zo.
En dergelijke samenvattingen maken lijkt me vrij geestdodend en duur. Automatiseren lijkt me een prima keuze. En voor de klant denk ik ook beter dan simpelweg overnemen van de ‘marketing’ kaft-tekst.
Wat ik ervan begrepen heb zijn de recensies in de meeste gevallen ook citaten van de achterflap met een regeltje mening van de ‘recensist’. Prima over te nemen door een ai.
En waarom moet nu juist ‘seks’ een van de vier criteria zijn? Ik kan er genoeg andere bedenken (discriminatie/sport/religie/politiek links of rechts/geografie/sociaal-cultureel milieu en nog wel 100) die net zo relevant, zo niet relevanter, zijn dan seks.
Ik zou de enige twee relevante criteria vinden: is het boek verrijkend of clichebevestigend, en hoe complex is boek het om te lezen. Ach, en misschien een indicatie van doel-leeftijd, why not, maar de rest is gewoon irrelevant.
En terwijl de extremen van de schuifjes bij stemming, seks en geweld nog te begrijpen zijn…. wat is in hemelsnaam ‘activiteit = relax of concentratie’? Is dat de activiteit van mij als lezer of van de hoofdpersoon? En is ‘concentratie’ wel een activiteit? De activiteit zou moeten zijn: ‘relaxen’ of ‘concentreren’, of desnoods ‘concentratie’ of ‘relaxatie’, maar niet ‘concentratie’ of ‘relax’. En waarom moet zo’n rare Engelse term gebruikt worden, die blijkbaar door de maker van het hulpmiddel al niet eens begrepen wordt?
Kortom, nog onafhankelijk van hoe de schuifjes staan, dus van de inhoud: WAT.EEN.DRAAK.VAN.EEN.RECENTIEHULPMIDDEL
Een van de ‘misverstanden’ is het woord ‘recensie’. Waar bibliotheken behoefte aan hebben is informatie op meta niveau op basis waarvan een keuze wordt gemaakt uit meer dan 15.000 nieuwe titels per jaar, plus een nog veel groter aanbod uit het buitenland. Dat gaat al lang niet meer op basis van ‘een mooie recensie’, zoals iedere uitgever kan beamen die een matige bibliotheek bestelling van zijn/haar boek krijgt ondanks de mooie recensie. En bibliotheken willen de informatie sneller. Het is overigens niet zo dat alle recensenten verdwijnen, er is nog genoeg dat niet door de machine kan. Maar in de praktijk blijkt dat dit systeem wat al geruime tijd ‘schaduw draait’ goed functioneert. En een goede recensie in een krant kan nog altijd helpen. Maar voor een bibliotheek gelden andere eisen dan alleen de recensie om een boek op te nemen in de collectie. Daar gaat dit om.
Uit een aan te bevelen column over AI’s en het aanschafbeleid van (openbare) bibliotheken:
“Volgens mij is een van de oorzaken van de verwarring het gebruik van het woord recensie en recensent. Daarmee krijgen veel buitenstaanders meteen die associatie van een inhoudelijk kwaliteitsoordeel en hoge kunst. Maar deze recensies heten niet voor niks ‘aanschafinformatie’, in de branche afgekort tot AI. Deze recensies moeten vooral iets zeggen over de bruikbaarheid van het boek voor de openbare bibliotheken.”
http://www.tenaanval.nl/een-ai-is-geen-recensie/