
Artificial Intelligence is wat een computer bijna kan, las ik ooit als definitie van die term. Want op het moment dat de computer het kan, is het gewoon een ding dat een computer kan. Er is maar een korte periode waarin een computer iets kan laten zien dat we nog echt nieuw vinden. Ik heb het gevoel dat we daar nu zitten met documentanalysetools zoals NDA Lynn: de tools bestaan, en ze kunnen dingen, maar we vinden het nog wel een beetje eng. Ik ben benieuwd of Edit Mode mensen over de streep trekt. Helemaal omdat het stiekem eigenlijk niet zo ingewikkeld is.
Ik heb gemerkt dat mensen enthousiast worden over nieuwe features of werkwijzen als je ze een catchy naam geeft, vandaar dat ik dit aspect Edit Mode heb genoemd (enige associatie met vim(1) is geheel toeval). Maar het is wel een forse andere manier van werken. In plaats van een rapport met bevindingen krijg je nu in je document bevindingen terug. In de vorm van commentaar in de marge, en in de vorm van een aangepaste clausule.
Dit heeft nogal wat voeten in de aarde, maar vooral in wat er allemaal omheen moet gebeuren. Ik rijd voor mijn werk dagelijks langs een grote bouwplaats. Daar gebeurt altijd weken niets, en dan zit er ineens een verdieping bovenop het gebouw. En laatst was ik er een week niet en toen bleken die betonnen platen te zijn bekleed, gestoffeerd en behangen. Morgen eerste bewoners. Nou, al dat werk aan die betonplaten en fundering dat is nu dus ongeveer gedaan.
In de oude versie werd alle tekst gewoon geëxtraheerd uit het brondocument. Daar zijn libraries te over voor. Die tekst werd dan geclassificeerd (“dit is security, dit gaat over overmacht, dit is een partijdefinitie”, etcetera etcetera) en daarna van een smaakje (streng, eenzijdig, breed, etc) voorzien. Dan nog even opzoeken wat dat betekent (“oké, eenzijdige partijdefinitie willen we niet”) en de uitvoer op je scherm. Duidelijk. Maar nu willen we dus terug het document in, en bij de zin over security een commentaartje hangen “Deze is te streng, dit willen we niet”). En dat was er dus niet, informatie om mee terug het document in te gaan.
Nu dus wel. We nemen dus het commentaar op de clausule en stoppen dat in een comment die in de marge verschijnt:

Ziet er gaaf uit, nietwaar? En ergens ook wel, eh, AI achtig, dat een robot gewoon doet wat een mens voorheen deed met zo’n tekst. De huidige teksten zijn nog geschreven als beschouwende analyse, maar je kunt ze ook net wat pittiger schrijven als pushback naar de opsteller van het document. En dan kun je daar nog een beetje GPT-3-achtige tekstvariaties bij laten maken en dan krijg je duidelijk een robot aan het woord.
Er zit nog een lastig aspect aan. We extraheerden dus die individuele zinnen, om daarmee vervolgens clausules te maken en die van commentaar te voorzien. Maar dan moet je dus terug in het document en dan kun je alleen de commentaren aan de individuele zinnen hangen. Dat gaat dan mis als twee zinnen uit dezelfde categorie na elkaar volgen. Dan krijg je twee keer hetzelfde commentaar achter elkaar. En “op elkaar volgen” is niet zo eenvoudig te herkennen. Word stopt er soms een héle trits codes tussen, waardoor het voor software lijkt of de twee zinnen drie kilometer uit elkaar staan.
De volgende stap: het document wijzigen. Oftewel, je hebt gezien dat een clausule onacceptabel is en je wilt er wat acceptabels van maken. Hoe pak je dat aan?
Als mens ga je dan op basis van ervaring zelf wat aanpassen. Hier een stukje redelijkheid, daar een “voor zover haalbaar zonder kosten” en zo nog wat braaftaal om al te strenge clausules rustig te krijgen. Of juist omgekeerd, je schrapt “inspanning” en je maakt er “garandeert” van, je voegt wat specifieke eisen toe en maakt het zo het gewenste niveau van strengheid. Automatiseer dat maar eens.
Die bedrijfsjuristen van gisteren hadden een nog iets ander idee: laat ons zelf clausules erin zetten, en schrap dan de onacceptabele clausule zodat ‘onze’ clausule erin geplakt gaat worden. Dát gaat hem niet worden. Dan moet je gewoon je eigen NDA opsturen als tegenvoorstel. Maar onderhandelingstechnisch staat het héél raar als je zegt “deze tekst kan niet, ik heb alles geschrapt en mijn tekst erin geplakt”. Daar kom je gewoon niet mee weg.
Nee, het moet met hier een stukje erbij en daar een stukje eraf. Gelukkig zijn er tools die dergelijke aanpassingen gewoon kunnen uitrekenen: gegeven brontekst A en doeltekst B, wat moet er in A bij of af om tot B te komen? Mijn probleem is dus alleen hoe je aan de juiste doelteksten B komt.
Dat is makkelijker dan je denkt, want ik had dus een hele bak met clausules die ook nog eens in verschillende smaakjes ingedeeld is. Dat is immers de dataset waarmee ik Lynn heb gevoed. Als ik nu uit elk smaakje een selectie maak, tien clausules van de brede soort, tien van de beperkte soort en tien van de standaard/gemiddelde soort, dan zijn we er. Kijk welke soort acceptabel is voor deze klant (bijvoorbeeld de brede smaak), pak een van die tien clausules van die smaak en pas de NDA aan zodat de onacceptabele clausule (bijvoorbeeld een beperkte) verandert in die ene van brede smaak.
Dan krijg je dus dit. En ja, dit is een redline gemaakt door NDA Lynn:

De originele tekst was een hele brede: alle informatie was geheim, ongeacht hoe deze was vastgelegd. Maar dat was niet acceptabel: het moest beperkt worden: alleen informatie waar “geheim” op staat valt onder de NDA. De aanpassing zorgt daarvoor, door een clausule uit de beperkte categorie te pakken en als een redline door te voeren.
Blijft nog over de business logic die erbij hoort. Want je kunt wel alles aanpassen, maar juist bij een NDA wil je niet op elke zin commentaar geven. Zowel jij als je wederpartij willen snel tekenen zodat je door kunt met je zakelijk gesprek. Vaak zie je dus dat je alleen van de échte problemen een punt maakt, zoals de hierboven getoonde definitie van vertrouwelijkheid. Maar dat jij een net wat mooiere manier hebt om te zeggen dat de rechtbank Amsterdam bevoegd is, dat laat je gewoon zitten. Dat kost alleen maar tijd.
Tegelijkertijd is dit wel een zakelijke feature en moet je een jurist overtuigen dat zhij dit wil. Dus dan kies je voor de tijdgeteste traditie van de afdeling Sales en maak je er een configuratie-optie van. Wat wil je voor dealbreakers; een edit of alleen een comment? En voor essentials? Het meest logisch – en dus de default – wordt dat dealbreakers een edit geven en essentials een comment.
En dan zijn we er eindelijk: jij uploadt je NDA met de vraag, ik ga informatie krijgen en kan ik deze tekenen? NDA Lynn zegt ja of nee, en zo nee dan krijg je de aanpassingen die naar je wederpartij kunnen. Ondertussen kan ik lekker écht werk doen. Dat is waar legal tech over gaat.
(Dit was deel vijf van vijf vakantieberichten.)
Arnoud

 Verder hadden we nog een mailinterface ingebouwd (forward je mail naar een speciaal adres en krijg de bevindingen teruggemaild) en een API koppeling gebouwd voor integratie van Lynn in andere diensten. Ik had mooie dromen om Lynn bijvoorbeeld aan Slack te koppelen: stuur haar een privébericht en ze reageert binnen een paar minuten in de chat met of je kunt tekenen of niet. Of nog leuker, een Outlook plugin of een koppeling met Salesforce. Stel je voor, je krijgt een mail met een NDA en in de sidebar staat meteen een bericht “deze kun je tekenen, no problem”. Maar ik had geen idéé hoe duur dat allemaal wel niet was.
Verder hadden we nog een mailinterface ingebouwd (forward je mail naar een speciaal adres en krijg de bevindingen teruggemaild) en een API koppeling gebouwd voor integratie van Lynn in andere diensten. Ik had mooie dromen om Lynn bijvoorbeeld aan Slack te koppelen: stuur haar een privébericht en ze reageert binnen een paar minuten in de chat met of je kunt tekenen of niet. Of nog leuker, een Outlook plugin of een koppeling met Salesforce. Stel je voor, je krijgt een mail met een NDA en in de sidebar staat meteen een bericht “deze kun je tekenen, no problem”. Maar ik had geen idéé hoe duur dat allemaal wel niet was.
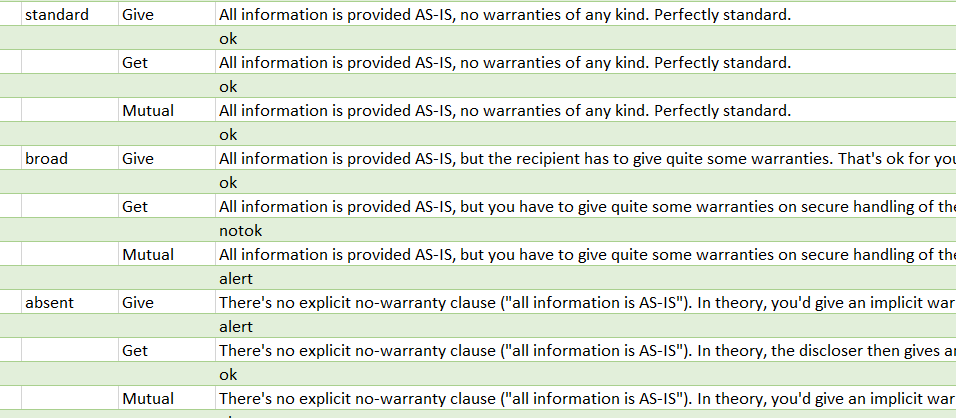 Blijft over: wat ga je zeggen. Daarvoor schrijf ik een uitvoertabel, die per clausule per smaak per situatie aangeeft wat het antwoord moet zijn. Hierboven zie je een klein stukje daarvan: dit is de uitvoer voor de categorie “warranties” oftewel garanties. Wat moet je zeggen als deze standaard of juist breed gevraagd worden, of als er geen garanties in staan. Je ziet dat het antwoord net anders is als je in de give dan wel in de get of mutual situatie zit.
Blijft over: wat ga je zeggen. Daarvoor schrijf ik een uitvoertabel, die per clausule per smaak per situatie aangeeft wat het antwoord moet zijn. Hierboven zie je een klein stukje daarvan: dit is de uitvoer voor de categorie “warranties” oftewel garanties. Wat moet je zeggen als deze standaard of juist breed gevraagd worden, of als er geen garanties in staan. Je ziet dat het antwoord net anders is als je in de give dan wel in de get of mutual situatie zit. De grootste fout die softwareontwikkelaars maken:
De grootste fout die softwareontwikkelaars maken:  Goed, robots kunnen dus
Goed, robots kunnen dus  Mijn blog van volgende week over het
Mijn blog van volgende week over het  Al jaren gaat het rond in de juridische sector: het wordt tijd om eens af te stappen van de billable hours oftewel het uurtje/factuurtje model. Klanten worden er nooit gelukkig van, het is een hoop gedoe voor medewerkers en het zou zo eenvoudig moeten zijn om gewoon een prijs te noemen. Maar toch blijft het maar gebruikt worden, een enkel experiment of uitzonderlijke case daargelaten. Daar zit inderdaad een probleem: wat moet het alternatief zijn? Maar op die vraag moet wel een antwoord komen, anders is het invoeren van nieuwe systemen (legal tech dus) gedoemd te mislukken.
Al jaren gaat het rond in de juridische sector: het wordt tijd om eens af te stappen van de billable hours oftewel het uurtje/factuurtje model. Klanten worden er nooit gelukkig van, het is een hoop gedoe voor medewerkers en het zou zo eenvoudig moeten zijn om gewoon een prijs te noemen. Maar toch blijft het maar gebruikt worden, een enkel experiment of uitzonderlijke case daargelaten. Daar zit inderdaad een probleem: wat moet het alternatief zijn? Maar op die vraag moet wel een antwoord komen, anders is het invoeren van nieuwe systemen (legal tech dus) gedoemd te mislukken.