 Heb je je wel eens afgevraagd hoe deze innovatie bijdraagt aan een afschuwelijke dystopie? Zo prikkelt machine learning engineer Sean McGregor zijn collega’s als die weer eens enthousiast doen over de inzet van AI voor het een of ander. Want maar al te vaak blijkt een goed idee uiteindelijk vooral nadelen voor kwetsbare mensen op te leveren of nodeloze rechtlijnigheid te introduceren in een op zich prima werkend menselijk proces. En om dat kracht bij te zetten, onderhoudt hij sinds een tijdje de AI Incident Database.
Heb je je wel eens afgevraagd hoe deze innovatie bijdraagt aan een afschuwelijke dystopie? Zo prikkelt machine learning engineer Sean McGregor zijn collega’s als die weer eens enthousiast doen over de inzet van AI voor het een of ander. Want maar al te vaak blijkt een goed idee uiteindelijk vooral nadelen voor kwetsbare mensen op te leveren of nodeloze rechtlijnigheid te introduceren in een op zich prima werkend menselijk proces. En om dat kracht bij te zetten, onderhoudt hij sinds een tijdje de AI Incident Database.
Zoals de site het zelf toelicht:
The AI Incident Database is a collection of harms or near harms realized in the real world by the deployment of intelligent systems. You are invited to submit reports to the database, whereupon accepted incidents will be indexed and made discoverable to people developing and deploying the next generation of AI technology to the world. Artificial intelligence will only be a benefit to people and society if we collectively record and learn from its failings. Learn more about the database, or read about it on the PAI Blog, Vice News, Venture Beat, and arXiv among other outlets.Soms gaat het om gewoon hilarische storingen, zoals een surveillancerobot die zichzelf de fontein in rijdt omdat hij water niet van tegels kon onderscheiden. Wat ook weer heel naar kan uitpakken, zoals bij de lasrobot die niet geprogrammeerd was om mensen te vermijden – en iemand doodde toen die een losgelaten metalen plaat wilde verwijderen.
De pijn zit hem vaker niet in zulke extreme dingen, maar in de vaak schimmige manier waarop een AI tot haar conclusie komt. Bijvoorbeeld omdat je geen uitleg krijgt, zoals bij incident 96 waar een door de fabrikant geheimgehouden algoritme leraren beoordeelt en laat ontslaan. Of bij incident 78, waar een studente geweigerd werd bij geneeskunde in Duitsland omdat de AI had ingeschat dat ze lage cijfers zou halen. Of bij incident 95 waarin gezichts- en stemanalyse ertoe leidt dat sollicitanten geweigerd worden.
Die laatste is interessant omdat de gebruikte data is geanalyseerd en vrij van bias zou zijn bevonden. Ja, ik ben skeptisch want ik geloof dat niet – bijvoorbeeld omdat ik me niet kan voorstellen dat men bij stemanalyses de moeite neemt om stotteraars of mensen met slokdarmspraak te vragen om een representatieve hoeveelheid data aan te leveren. (De kans is groter dat men het ding op porno getraind heeft, daar is immers veel sneller een grote hoeveelheid data voor te krijgen.)
Dat gebrek aan representativiteit zie je vaak opduiken. Bijvoorbeeld in incident 48, waarbij paspoortfoto’s worden gescreend op “ogen volledig open” wat natuurlijk misgaat bij Aziatische mensen. Die overigens ook niet hoog scoren in beauty contests waarbij een AI de jury speelt. Op het gorilla-incident van Google hoef ik al helemaal niet op in te gaan. Het aantal voorbeelden is talrijk.
De vraag is, hoe moet het dan wel. Daar zijn alweer eventjes geleden de EU Ethics Guidelines for trustworthy AI voor geformuleerd. Deze bevatten geen juridische eisen (die komen er wel aan, de Verordening AI) maar juist ethische kaders: hoe moet het wel, wat mag de burger verwachten en wat moet een bouwer of gebruiker van AI aan verplichtingen op zich nemen.
Wie wil leren hoe dat werkt: op 20 september start mijn tienweekse cursus AI Compliance in de praktijk weer. Leer in je eigen tijd (ongeveer 4 uur per week) de techniek én de ethische kaders rondom AI, met echte cases en echte data. Ik laat je zoeken naar bias in een dataset met leningaanvragen of puzzelen over waarom een snel en vrijwillig AI-loket bij de gemeente in strijd is met de mensenrechten. En ondertussen zet je je ook in om de gemeente Juinen met haar miljoenen kostende AI initiatieven hoog in de wereldranglijst te krijgen. Wees er snel bij!
Arnoud
 “Ik zat dit weekend nog eens te lezen maar kwam er toen achter dat deze api helemaal niet gratis is en dat elke call een paar centen kost. Nu zijn alle calls al gemaakt en heb ik berekend dat er ongeveer $40.000 in rekening gebracht zal worden… oeps”. Dat
“Ik zat dit weekend nog eens te lezen maar kwam er toen achter dat deze api helemaal niet gratis is en dat elke call een paar centen kost. Nu zijn alle calls al gemaakt en heb ik berekend dat er ongeveer $40.000 in rekening gebracht zal worden… oeps”. Dat  Een lezer vroeg me:
Een lezer vroeg me: Een lezer vroeg me:
Een lezer vroeg me: Een lezer vroeg me:
Een lezer vroeg me: Een lezer vroeg me:
Een lezer vroeg me: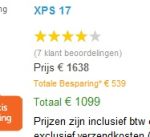 Gaan we weer een keer: nu is het Dell dat een hele strakke aanbieding doet en vervolgens annuleert omdat de prijs een fout lijkt te zijn geweest. Bij Tweakers
Gaan we weer een keer: nu is het Dell dat een hele strakke aanbieding doet en vervolgens annuleert omdat de prijs een fout lijkt te zijn geweest. Bij Tweakers 
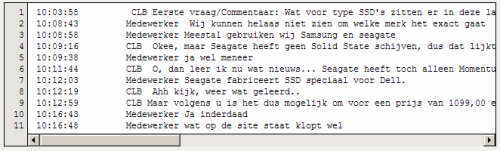
 Een lezer vroeg me:
Een lezer vroeg me: